Object Views.
Interfaces are to implementation classes as database views are to tables
I'm working with a team on which this design has emerged...
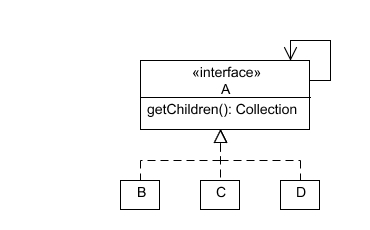
Essentially this supports a tree of A's, with nodes implemented by B, C and D.
The DBA on the team was concerned that this design did not accurately reflect the fact that B was fundamentally different from C and D, which were more alike. The root node could only be a B, but B, C and D could all be leaf nodes. I was trying to explain that while B, C and D appear equal in this diagram, the rules that separate them could be expressed in the implementing classes. Clients of A don't care that only B can be a root node. Clients of B do, but clients of A don't.
He also added that there are additional methods on B that don't apply to A. So we added E to the mix...
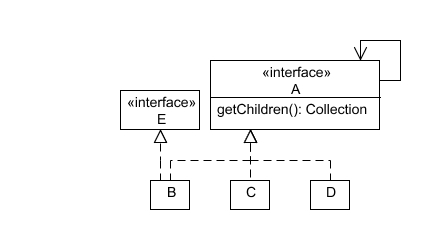
I was struggling to help the DBA understand that this structure allowed us to view a B as an A or an E when I told him to think of it like a view in a database. This helped a lot to clarify what was going on for him, and it also led me to explore the analogy further.
What is the purpose of an interface? There are likely several answers but the one I'm interested in this context is that it is an abstraction that isolates the client code from the implementation details. Even that answer can be broken down into two answers:
* the client code need not be changed when implementation changes
* the developer working on the client code need not concern himself with implementation details
In the latter, the person working on the client code just sees an E. So the E interface simplifies the "conceptual weight"* that the developer must bear when dealing with an instance of B. To her it's just a simple E. In a sense, you could say that it clarifies the meaning of what a B from the perspective code or a person that is interested in an E.
Similarly, a database view...
* serves to present complex data in a more human-understandable form - typically through de-normalization.
* isolates client code from the normalized structure (implementation detail) of the underlying data.
The thing that I like about this analogy is that most developers (object and data) understand why it's helpful to represent data in a denormalized fashion - it's easier to read from the outside. And there are often many views of the same data, especially in applications that have a lot of reports. When you add a report you can just add a new view into the same data. If the underlying tables change in any way, code need not change because it relies on the view, not the tables.
Conversely, in my experience, developers often come to interfaces from the bottom up. TDD even guides us to do that: create a class, create a second class, recognize their similarities and abstract the similarities up to an interface. This serves to minimize duplication, but it doesn't deal with the external view. The fact that you can look at a B as an A or an E is every bit as powerful as our ability to present multiple views of data stored in database tables.
* Joshua Bloch's Effective Java talks about "conceptual weight" being a factor in determining how long it will take to learn the API.
* The above diagrams were created with UMLet
!commentForm
This sounds good to me. I'll use it in my talks. We should figure out the ways of how to cross from data
point of view to object and behavior point of view.
point of view to object and behavior point of view.
I like the correlation between segregated interfaces and database views. There is a deep symmetry there which adds to the symmetry that already exists between tables and objects.
objects |
data |
| Objects hide data and present behavior | tables present data and have no behavior |
| Objects are partitioned based upon behavior relationships | tables are partitioned based upon data relationships. |
| Objects are viewed through interfaces they depend upon | tables are viewed through views they don't depend upon. |
Add to that list the fact that composition is typically expressed in opposite ways in objects and tables. A Person object with 3 PhoneNumbers[?] has a Collection of PhoneNumbers[?]. Conversely, the same relationship is expressed in database tables with a foreign key from the phone_number table to the person table. So Person objects know their phone numbers, but rows in phone_number know their person.
What do you think about this reverse dependency? An application is built on an object model and data model. These two distinct models are correlated somehow. But dependencies in these two models are reverse of each other. In crossing this mapping rubiccon, is it a great problem? Sometimes, makes transparent mapping impossible.
I have been using database views for a long time. Also, writing code in SQL I had always used PL/SQL packages which are akin to classes and have their private and public objects (data elements, procedures, functions, etc.) So, quite a few years ago, when I started reading about OO my reaction was, "So what? We've been doing that all along!" Except for inheritance, there is nothing in OO that has not been done by good programmers elsewhere, using non-OO paradigms.
Today, OO proponents seem to think that information hiding and other good software design practices are possible only using OO. All it tells me is that, if they had ever done any other type of programming, they were never good programmers. Which means that even after moving to OO they will not suddenly be transformed to good OO programmers.
Talking of inheritance, the more I use OO the less need I feel for it. My designs have very little inheritance, mostly composition seems to work. For me, that means, one of the supposed benefits of OO is not so beneficial since it is used rarely.
Every other software design principle can be implemented using other paradigms, and good design, and a tendency to think of a lot of things as data, not code. Which reduces the code a lot, and results in reusable software.
Today, OO proponents seem to think that information hiding and other good software design practices are possible only using OO. All it tells me is that, if they had ever done any other type of programming, they were never good programmers. Which means that even after moving to OO they will not suddenly be transformed to good OO programmers.
Talking of inheritance, the more I use OO the less need I feel for it. My designs have very little inheritance, mostly composition seems to work. For me, that means, one of the supposed benefits of OO is not so beneficial since it is used rarely.
Every other software design principle can be implemented using other paradigms, and good design, and a tendency to think of a lot of things as data, not code. Which reduces the code a lot, and results in reusable software.
In a comment, David C wrote, "So Person objects knowtheir phone numbers, but rows in phone_number know their person."
While true, that is not necessarily good database design. A tenet of good software development is that names should be meaningful, and atomic in the sense that an object (or entity or method) must do exactly one thing. If I came across the requirement that a person can have multiple phone numbers, then I'd implement it using a many-to-many relationship and an intersection entity. Thus, my tables would be Person, Phone, and Person_Phone. Even if we were to use only two tables, they would be called Person and Person_Phone which better conveys the intent of the design than the name Phone.
Of course, the opriginal issue has not gone away: How do we map the data model to the object model?
Once again, views can come to the rescue. If your RDBMS supports having a collection as a field, (such as Varrays or Nested Tables in Oracle) then you can have views that mimic the object structure and have "Instead of" Triggers written for the views that will move the data to the correct place.
Of course, this means that code used to allocate the data to the correct tables is written in the database, which, to a true OO believer, is sacrilege! But it keeps the code that deals with the database structures in the database, and code that deals with the business logic in the business layer.
The Java developer codes in a call to insert the data into the view, while the database developer handles it form there on. We now get a clear separation of concerns and the right abstraction for the Java developer without worrying about the database implementation details.
While true, that is not necessarily good database design. A tenet of good software development is that names should be meaningful, and atomic in the sense that an object (or entity or method) must do exactly one thing. If I came across the requirement that a person can have multiple phone numbers, then I'd implement it using a many-to-many relationship and an intersection entity. Thus, my tables would be Person, Phone, and Person_Phone. Even if we were to use only two tables, they would be called Person and Person_Phone which better conveys the intent of the design than the name Phone.
Of course, the opriginal issue has not gone away: How do we map the data model to the object model?
Once again, views can come to the rescue. If your RDBMS supports having a collection as a field, (such as Varrays or Nested Tables in Oracle) then you can have views that mimic the object structure and have "Instead of" Triggers written for the views that will move the data to the correct place.
Of course, this means that code used to allocate the data to the correct tables is written in the database, which, to a true OO believer, is sacrilege! But it keeps the code that deals with the database structures in the database, and code that deals with the business logic in the business layer.
The Java developer codes in a call to insert the data into the view, while the database developer handles it form there on. We now get a clear separation of concerns and the right abstraction for the Java developer without worrying about the database implementation details.
- Ravi said: Except for inheritance, there is nothing in OO that has not been done by good programmers elsewhere, using non-OO paradigms.
Although it is true that programmers have been using one form of polymorphism or another for years (especially assembly language programmers who build their own jump tables) it is only with the advent of OO that polymorphism has become a mainstream tool. What's more, it is the tool that give OO it's biggest benefits. It is through the use of polymorphism that we are able to manage dependencies.
Inheritance is one possible mechanism for providing polymorphism to languages. It is heavily used in statically typed langauges like Java, C++, and C#. However, in dyanmic languages like Smalltalk, Python, and Ruby, inheritance is a relatively unimportant features since polymorphism is achieved without it.
UncleBob[?] said: However, in dyanmic languages like Smalltalk, Python, and Ruby, inheritance is a relatively unimportant features since polymorphism is achieved without it.
Does this mean that two designers developing class diagrams for the same project, one using any of Java/C++/C# and the other using any of Smalltalk/Python/Ruby will end up with significantly different designs?
That's what it seems to imply. I develop in Java, and yet use inheritance only when absolutely needed. Seems to work for me. Seldom will any of my inheritance hierarchies be more than two layers deep, excluding the root.
Does this mean that two designers developing class diagrams for the same project, one using any of Java/C++/C# and the other using any of Smalltalk/Python/Ruby will end up with significantly different designs?
That's what it seems to imply. I develop in Java, and yet use inheritance only when absolutely needed. Seems to work for me. Seldom will any of my inheritance hierarchies be more than two layers deep, excluding the root.
Two designers working in the same language might come up with significantly different designs. That's one of the beauties of software - that you can express the same requirements in many different, yet valid ways.
As for avoiding inheritance, the dependency inversion principle suggests that you shouldn't inherit from concrete classes. This naturally leads to very shallow hierarchies with concrete classes only living as leaves in the tree.
As Bob pointed out, the real power is polymorphism and while inheritance supports that, it's really just a means to that end.
Ravi - one thing I'm curious about is why you would impose a many to many relationship (using the person_phone table a few comments up) when the requirement is one to many? Doesn't this add unnecessary complexity?
As for avoiding inheritance, the dependency inversion principle suggests that you shouldn't inherit from concrete classes. This naturally leads to very shallow hierarchies with concrete classes only living as leaves in the tree.
As Bob pointed out, the real power is polymorphism and while inheritance supports that, it's really just a means to that end.
Ravi - one thing I'm curious about is why you would impose a many to many relationship (using the person_phone table a few comments up) when the requirement is one to many? Doesn't this add unnecessary complexity?
Ravi says "Every other software design principle can be implemented using other paradigms, and good design, and a tendency to think of a lot of things as data, not code. Which reduces the code a lot, and results in reusable software."
Data has this nasty tendency to change. If the dependencies are on data then a change there has a big ripple effect. Think of the Y2K[?] ripple effect of the year only having two digits. That dependendency caused some very non-reusable code.
Data has this nasty tendency to change. If the dependencies are on data then a change there has a big ripple effect. Think of the Y2K[?] ripple effect of the year only having two digits. That dependendency caused some very non-reusable code.
The decision to go for a many to many relationship would be based on past experience. Almost always demographic information such as addresses and phones end up being many to many anyway. What is the cost of doing it now? Very little, especially since this is more or less "done" and can be leveraged from previous projects.
Yes, precisely because data has a tendency to change, I try to exclude direct references to data from my code.
When the structure of the data changes, there is nothing to be done but handle the changes in code. But when the values held by the data elements change, or the number of elements for a data category change, then we do not have to change the code.
For example, I see so much code that says something like:
private static final String SUCCESS = "S";
private static final String FAILURE = "F";
...
While this works for now, when we want to add a new status, or we want to change the display of the status to the full meaning of the variables, we must change the code to add a new status. Also, for any reason whatsoever, if we must change the values of the Strings, (from "S" to "Success", say) we'll have to change the code.
I prefer something a bit more abstract that does not create a series of Strings. I may have a map with "status.success", "status.failure", etc. as keys. The values for the map would be read from some sort of configuration source. Adding a new status would not necessarily require me to change the class, just the data source would need to be changed.
If we were using the status to redirect a web page, then adding a new type of status would not require any code change. Our redirection code would be something like:
page.redirect(status, getRedirectionPage(status));
where the redirection page could be obtained from another configuration file.
[Strictly speaking, the above call would be more like
page.redirectBasedOnStatus(status);
with the getRedirectionPage(status) call hidden in the redirect method.]
Also, the intent of the code comes across very clearly in this example.
Of course, this is a trivial example, and does not really show the point of avoiding hard coded names.
On a project, we had been told that the users were thinking of a particular value as "Needs" and then decided to change the name to "Upcoming Events". A lot of programming was based on this value and other values in the same category. Since we had modelled this as data, and not code, we could make the change very easily simply by changing the data source values. (Our code did things based on the values, but what to do was itself data, not code!) Had we had code that depended on any particular name, we'd have had to spend quite a bit more time making changes.
Another important thing happens when we think of a lot of things as data: we tend to see the common features and code accordingly. In essence, we end up assuming very little, and hence, restricting very little. The end result is often a very powerful application that handles change very, very easily.
Note also that this design philosophy leads to a lot fewer classes. In the above status example, there would not even be a thought of creatiing a Status Interface (or AbstractClass[?] or SuperClass[?]) and simple classes called FailureStatus[?], SuccessStatus[?], etc. The resulting code is also much simpler, I think.
When the structure of the data changes, there is nothing to be done but handle the changes in code. But when the values held by the data elements change, or the number of elements for a data category change, then we do not have to change the code.
For example, I see so much code that says something like:
private static final String SUCCESS = "S";
private static final String FAILURE = "F";
...
While this works for now, when we want to add a new status, or we want to change the display of the status to the full meaning of the variables, we must change the code to add a new status. Also, for any reason whatsoever, if we must change the values of the Strings, (from "S" to "Success", say) we'll have to change the code.
I prefer something a bit more abstract that does not create a series of Strings. I may have a map with "status.success", "status.failure", etc. as keys. The values for the map would be read from some sort of configuration source. Adding a new status would not necessarily require me to change the class, just the data source would need to be changed.
If we were using the status to redirect a web page, then adding a new type of status would not require any code change. Our redirection code would be something like:
page.redirect(status, getRedirectionPage(status));
where the redirection page could be obtained from another configuration file.
[Strictly speaking, the above call would be more like
page.redirectBasedOnStatus(status);
with the getRedirectionPage(status) call hidden in the redirect method.]
Also, the intent of the code comes across very clearly in this example.
Of course, this is a trivial example, and does not really show the point of avoiding hard coded names.
On a project, we had been told that the users were thinking of a particular value as "Needs" and then decided to change the name to "Upcoming Events". A lot of programming was based on this value and other values in the same category. Since we had modelled this as data, and not code, we could make the change very easily simply by changing the data source values. (Our code did things based on the values, but what to do was itself data, not code!) Had we had code that depended on any particular name, we'd have had to spend quite a bit more time making changes.
Another important thing happens when we think of a lot of things as data: we tend to see the common features and code accordingly. In essence, we end up assuming very little, and hence, restricting very little. The end result is often a very powerful application that handles change very, very easily.
Note also that this design philosophy leads to a lot fewer classes. In the above status example, there would not even be a thought of creatiing a Status Interface (or AbstractClass[?] or SuperClass[?]) and simple classes called FailureStatus[?], SuccessStatus[?], etc. The resulting code is also much simpler, I think.
In answer to James Grenning's comment about data dependencies causing the Y2K[?] problem.
Y2K[?] was caused not by data centric programming but because of the limitations imposed by programmers in their code.
The Y2K[?] problem arose because the application code interpreted 2 digit years to belong to the current century, when the century changed, code that was working earlier could/might have failed. Application code's attempts to interpret a string (or character array) as a date was the thing that caused the most problems. Not Data per se. Incorrect use of data was the cause, I feel.
Today, almost all languages have a Date data type that can handle dates and timestamps. We, today's programmers, never have to worry about how the dates are stored, how much space is used by each date object, etc.
Have we really learned from Y2K[?]? I am not sure. There are still many applications that will interpret "05" as "2005". What if I wanted to enter the year of my grandfather's birth as 1905 and absentmindedly type in "05"? The application will accept it and cause problems for me later when it turns out that my granfather is younger than me!
Java is a big culprit in this respect. It will accept a value of, say, "13-32-2004" and silently convert it to "Feb 02, 2005" adding the necessary days and months and changing the year as needed. That is totally counter-intuitive. If I type in 32 for the day of the month, I want my application to stop working immediately, and raise an error. This, again, has nothing to do with data but the code that does not validate the date properly.
Y2K[?] was caused not by data centric programming but because of the limitations imposed by programmers in their code.
The Y2K[?] problem arose because the application code interpreted 2 digit years to belong to the current century, when the century changed, code that was working earlier could/might have failed. Application code's attempts to interpret a string (or character array) as a date was the thing that caused the most problems. Not Data per se. Incorrect use of data was the cause, I feel.
Today, almost all languages have a Date data type that can handle dates and timestamps. We, today's programmers, never have to worry about how the dates are stored, how much space is used by each date object, etc.
Have we really learned from Y2K[?]? I am not sure. There are still many applications that will interpret "05" as "2005". What if I wanted to enter the year of my grandfather's birth as 1905 and absentmindedly type in "05"? The application will accept it and cause problems for me later when it turns out that my granfather is younger than me!
Java is a big culprit in this respect. It will accept a value of, say, "13-32-2004" and silently convert it to "Feb 02, 2005" adding the necessary days and months and changing the year as needed. That is totally counter-intuitive. If I type in 32 for the day of the month, I want my application to stop working immediately, and raise an error. This, again, has nothing to do with data but the code that does not validate the date properly.
Ravi asked: Does this mean that two designers developing class diagrams for the same project, one using any of Java/C++/C# and the other using any of Smalltalk/Python/Ruby will end up with significantly different designs?
Yes. Designs in Smalltalk, Ruby, or Python are often quite different from designs in Java, C#, or C++. Dynamic typing makes a big difference in the way you conceive of the structure of a system.
Yes. Designs in Smalltalk, Ruby, or Python are often quite different from designs in Java, C#, or C++. Dynamic typing makes a big difference in the way you conceive of the structure of a system.
That is interesting. If we were designing data models for an application, the designs of the logical model would not be significantly different. The logical model is independent of the database chosen. When implementing for a particular database, there will be some minor differences in the physical models. But, the two physical models would look similar.
Two different designers intent on meeting requirements and applying the rules of normalization are likely to come up with very similar designs.
That said, when code is written in the database (using PL/SQL, T-SQL, Postgres's plpgsql, etc.), it is definitely influenced by what you can do with the languages supported by the database. But the underlying model could be the same.
This brings me to my question (mainly rhetorical): what exactly is an object model if it can be significantly different when using different languages. Can we not design a common object model of the software and then decide what language to use?
Pre-selecting the language may result in cumbersome designs. Doing design first, and then seeing what language can fit the needs might lead to better solutions.
These are just some thoughts I have. I am not arguing for or against any paradigm. Just asking questions and trying to learn.
Also, does this not imply that projects that try to convert from one OO language implementation to another (C++ to Java, etc.) are better redeveloped, rather than try to fit square pegs into round holes?
Two different designers intent on meeting requirements and applying the rules of normalization are likely to come up with very similar designs.
That said, when code is written in the database (using PL/SQL, T-SQL, Postgres's plpgsql, etc.), it is definitely influenced by what you can do with the languages supported by the database. But the underlying model could be the same.
This brings me to my question (mainly rhetorical): what exactly is an object model if it can be significantly different when using different languages. Can we not design a common object model of the software and then decide what language to use?
Pre-selecting the language may result in cumbersome designs. Doing design first, and then seeing what language can fit the needs might lead to better solutions.
These are just some thoughts I have. I am not arguing for or against any paradigm. Just asking questions and trying to learn.
Also, does this not imply that projects that try to convert from one OO language implementation to another (C++ to Java, etc.) are better redeveloped, rather than try to fit square pegs into round holes?
Ravi - what you're talking about sounds like Domain Model to me, not Object Model. The distinction being that Domain Model is going to be a bunch of objects that "model" the real world object in the specific domain - an Account in a banking app, for example.
In agile development, we are fond of saying "the code is the design". While there may be some discussion about what we may want in a design before we develop the code, we're going to learn things as we code and the resulting design may end up very different from the initial design. Also, we're constantly evolving the design to adapt to new requirements. So the best expression of the design is the current codebase. In that sense, the code is the design.
That said, while we may end up with a similar Domain Model across languages, the structure of the implementation hierarchy below the interfaces is likely to differ greatly from language to language. In fact, it arguably should differ to take advantages of each language's unique features.
In agile development, we are fond of saying "the code is the design". While there may be some discussion about what we may want in a design before we develop the code, we're going to learn things as we code and the resulting design may end up very different from the initial design. Also, we're constantly evolving the design to adapt to new requirements. So the best expression of the design is the current codebase. In that sense, the code is the design.
That said, while we may end up with a similar Domain Model across languages, the structure of the implementation hierarchy below the interfaces is likely to differ greatly from language to language. In fact, it arguably should differ to take advantages of each language's unique features.
OK, so if I were to draw an analogy between developing using procedural languages/RDBMS and OO paradigm, would it be correct to say that a Conceptual/Logical Model corresponds to a Domain Model (not dependent on the implmentation) while the Object Model corresponds to the actual code (C/T-SQL/PL-SQL/COBOL etc.) used to implement the business/domain logic?
Would it not be an advantage to use a language that can implement the domain model with its semantics as close to the domain model as possible? Or, when such a language is not available, to build one? Thus, a language that permits us to easily build the domain specific language would seem to be a good candidate for implementing the domain mode.
I think I should finish reading Eric Evans book about the Domain Model and try to gain some insights.
Would it not be an advantage to use a language that can implement the domain model with its semantics as close to the domain model as possible? Or, when such a language is not available, to build one? Thus, a language that permits us to easily build the domain specific language would seem to be a good candidate for implementing the domain mode.
I think I should finish reading Eric Evans book about the Domain Model and try to gain some insights.
Add Child Page to ObjectViews