The Perverse Nature of Performance Tuning
Many years ago I was working on an application in C++. My parter (at the time), Jim Newkirk, came to me and told me that one of our common functions was very slow. This function converted a binary representation of a data tree to text to be stored in a file. (This was before XML, but the concept is the same).I looked at this function for some time and realized that there was a linear symbol table lookup. So I confidently replaced the linear search with a binary search and gave the function back to Jim. Jim returned some hours later asking me whether I had made any changes or not, because the function was just as slow as ever.
This made no sense to me so I studied and studied the function and found a few other obvious algorithic changes to make. Yet nothing I did made the slightest difference. The function remained abyssmally slow, and Jim grew ever more frustrated with my useless flailings with this function.
Eventually Jim figured out how to profile the function and found that the problem was in a low level C++ library (strstream) which was allocating and reallocating and reallocating blocks as our text representation gradually grew. The function was increased in speed by orders of magnitude simply by preallocating the buffer that the text representation was to be loaded into.
Once, long ago, I had to write an algorithm to calculate the area of an arbitrary polygon. I concieved upon a notion of repeatedly subdividing the polygon into triangles. Each triangle would eliminate one vertex of the polygon and its area could be added to the growing sum. It took awhile to get this working because I had to deal with many irregular shapes. Still, after a day or two I had a very nice function that would calculate the area of any polygon at all.
A few days later one of my co-workers came to me and said: "It takes 45 minutes to calculate the area of the property line I'm drawing, so I can't display the area while the property line is being drawn or editted." 45 min. is a long time, so I asked her how many vertices the polygon had. She told me that it had over a thousand.
Looking at my algorithm I realized that it was O(N^3) and so was very fast for small polygons but impossibly slow for large polygons. I thought and thought about this problem but could not find a better solution. (Nowadays I'd just google for it, but that's now and this was then...) So we turned of the automatic display off area and told our customer it was too time consuming.
Two weeks later, by sheer happenstance, I was thumbing through a book on prolog (a lovely and strange langage that I recommend you learn!) and saw an algorithm for finding the area of a polygon. It was elegant, simple, and linear. It never would have occurred to me. I implemented it in a matter of a few minutes and, voila! we had real-time update of polygon area while dragging vertices accross the screen.
Last night I was sitting in a Limo, driving back from O'Hare to my home in the northern suburbs of Chicago. I-294 had some construction and we wound up caught in a traffic jam. So I pulled out my Macbook Pro and started writing a random Ruby program. I wrote the Sieve of Eratosthenes, just for grins. Once I got it working I decided to see just how fast Ruby is, so I augmented the program with benchmarks to measure it's speed. It was pretty fast! I could calculate all the primes less than a million in under two seconds! Not bad for an interpreted language.
I wondered what the O(x) of this algorithm was. Sitting in the car I could not look it up, so I decided to measure it by plotting some points. So I ran the algorithm from 100,000 to 5,000,000 in increments of 100,000. Then I ploted those points on a graph. Linear!.
How could this algorithm be linear? It's got a nested loop! Doesn't it have to be some kind of O(N^2) or at least O(N log N)? Here's the code, check for yourself:
require 'benchmark'
def sievePerformance(n)
r = Benchmark.realtime() do
sieve = Array.new(n,true)
sieve[0..1] = [false,false]
2.upto(n) do |i|
if sieve[i]
(2*i).step(n,i) do |j|
sieve[j] = false
end
end
end
end
r
end
My son, Micah, was sitting next to me in the Limo, and he leaned over and said: "The loop should only go up to the square root of n." I sheepishly realized that this must be the reason for the linearity. The loop was being swamped by the useless linear iterations all the way up to n when it should have been terminated just as it reached the root of n.
Not only would this change show the true curve of the performance graph, but it should substantially increase the speed of the algorithm. So I made the simple change:
require 'benchmark'
def sievePerformance(n)
r = Benchmark.realtime() do
sieve = Array.new(n,true)
sieve[0..1] = [false,false]
2.upto(Integer(Math.sqrt(n)) do |i|
if sieve[i]
(2*i).step(n,i) do |j|
sieve[j] = false
end
end
end
end
r
end
When I plotted the two graphs together, this is what I got:
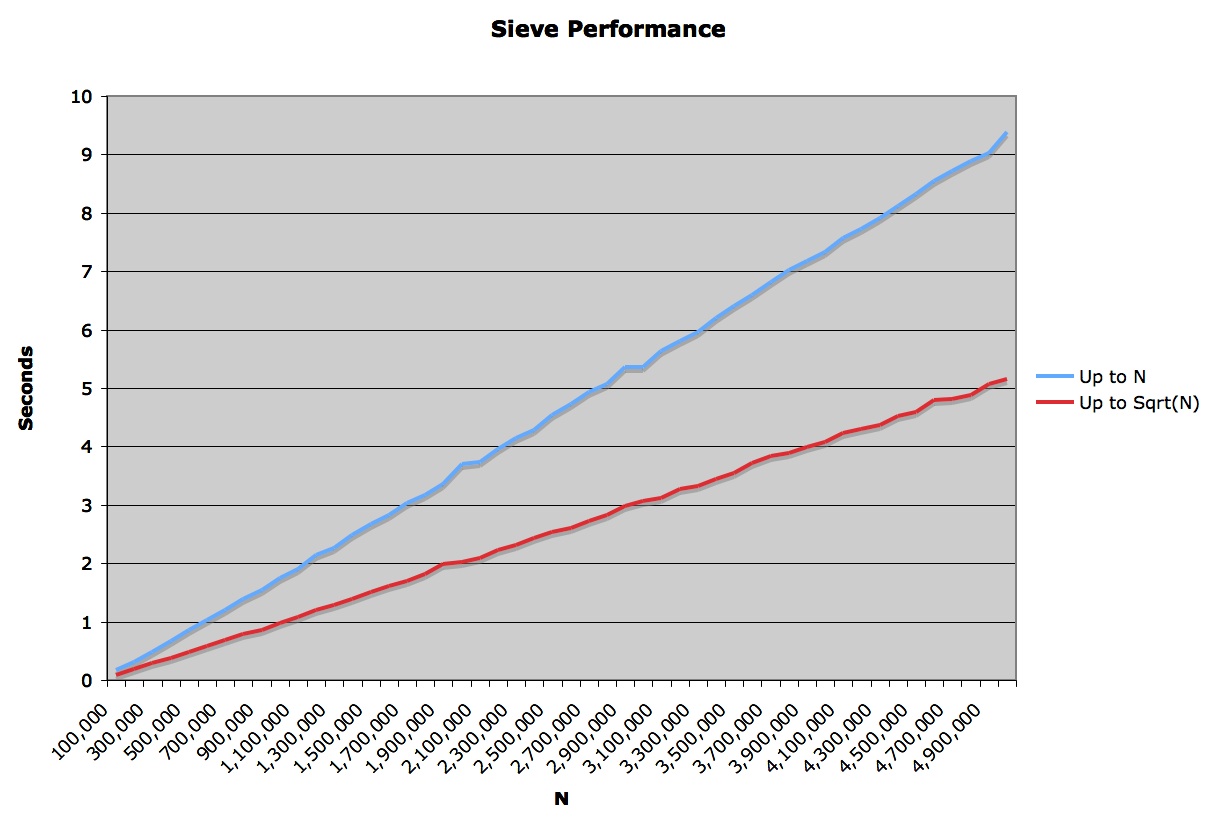
This was really disappointing. Firstly, there was no curve exposed in the sqrt(n) graph. Secondly, the sqrt(n) performance was only twice the speed of the original! How could a function whose outer loop had just had its exponent halved yeild just a linear (2X) increase in speed?
As I looked more at the algorithm I realized that as the iterator for the outer loop increases, the time for the inner loop decreases for two reasons. First, the step is larger. Second there are more 'false' values in the sieve so the if statement fires less often. This decreasing effect must somehow balance things such that the behavior of the algorithm remains linear.
I'm not a computer scientist, and am not really interested in doing the math to figure out whether this algorithm is really linear or not. The graph tells me what I need to know. For all intents and purposes the performance of this algorithm is linear.
All this just leads back to the title. Performance tuning is perverse. What you think is going on is seldom what really is going on. Who could have guessed that limiting the outer iteration to the square root of the maximum would yeild just a 2X increase in performance? Who could have guessed that the algorithm itself was linear?!
Six year ago, at the very first XP Immersion, I wrote a Sieve algorithm in Java as an example for Kent Beck to refactor in front of a group of 30-odd students. I watched in horror as he removed the clever sqrt from the function and replaced it with n. He said "I don't know if that'll really make the algorithm much faster and anyway setting the limit to n is much simpler and easier to read." So he deleted the fancy comment I had placed around the sqrt that explained why it was so clever and set the limit to n.
At the time I rolled my eyes to myself and silently smirked. I was certain that the sqrt would make the algorithm orders of magnitude faster for large n. I was convinced that every hundred-fold increase of n would yeild only a 10-fold increase in time. Six years later I finally measured that assumption and found that the increase was a linear factor of two, and that Kent was right all along.
Perverse!
!commentForm -r
I always keep the quote by Ron Jeffries, from the Refactoring book close at hand:
"The lesson is: Even if you know exactly what is going on in you system, measure performance, don't speculate. You'll learn something, and nine times out of ten, it won't be that you were right!!"
How true - I've always thought about putting that on the wall somewhere prominent..!
"The lesson is: Even if you know exactly what is going on in you system, measure performance, don't speculate. You'll learn something, and nine times out of ten, it won't be that you were right!!"
How true - I've always thought about putting that on the wall somewhere prominent..!
My performance tuning motto (which I periodically forget because I think I'm so smart):
Measure twice, cut (code) once.
Measure twice, cut (code) once.
Actually, the complexity of the sieve is O(n ln ln n). If you graph this you'll see it's all but indistinguishable from linear above n=0, even for quite large n. Still, it's a little bit bigger than O(n).
Nice post. Profiling is generally better than guessing :)
Nice post. Profiling is generally better than guessing :)
(Coincidentally, I was just reading that very chapter of <a href="http://www.amazon.com/gp/product/0135974445/"><cite>Agile Software Development</cite></a> today.)
I note that you can start the loops from (i*i) rather than (2*i), because you have already sieved out all the multiples of every prime less than i.
As in your example, this seems enticing from an optimization point of view, but doesn't actually give you much of a boost when you measure it - I'm seeing about 20% faster for the n-version, and only 3% faster for the sqrt(n)-version, even less impact than the n to sqrt(n) change. Ironically though, since this tweak seems to capture the intent of the sieve algorithm better, I'd advocate it even though I side with Beck on not doing the n to sqrt(n) change.
I note that you can start the loops from (i*i) rather than (2*i), because you have already sieved out all the multiples of every prime less than i.
As in your example, this seems enticing from an optimization point of view, but doesn't actually give you much of a boost when you measure it - I'm seeing about 20% faster for the n-version, and only 3% faster for the sqrt(n)-version, even less impact than the n to sqrt(n) change. Ironically though, since this tweak seems to capture the intent of the sieve algorithm better, I'd advocate it even though I side with Beck on not doing the n to sqrt(n) change.
Add Child Page to PerformanceTuning