Concepts That Don't Like To Be Named
Standard C has a function called atoi. It takes an int and converts it to an ASCII string.
There's another function called itoa that does the reverse. Unfortunately, it isn't part of standard C, it's just implemented roughly the same way in many C libraries. It takes a value to convert, a buffer to write the string representation into, and a radix. The return value is just a pointer to the buffer that you pass in:
char *itoa(int value, char *out_buffer, int radix);
Nice generality there with the radix, but if you don't have itoa and you only care about a radix of ten, you may be tempted to write something simpler, an itoa10 function.. something you can knock off very quickly.. and along the way you might find concepts that don't like to be named..
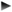
/* We need to return "0" when we convert 0 */
STRCMP_EQUALS("0", itoa10(0, buffer));
char *itoa10(int value, char *buffer) {
char *result = buffer;
*buffer++ = '0';
*buffer = '\0';
return result;
}
/* We need to return "1" when we convert 1 */
STRCMP_EQUALS("1", itoa10(1, buffer));
char *itoa10(int value, char *buffer) {
char *result = buffer;
*buffer++ = '0' + value;
*buffer = '\0';
return result;
}
/* We need to return "10" when we convert 10, which
is kind of tricky, but we can create "01" easily enough */
STRCMP_EQUALS("01", itoa10(10, buffer));
char *itoa10(int value, char *buffer)
{
char *result = buffer;
do {
*buffer++ = '0' + value % 10;
value /= 10;
} while (value > 0);
*buffer = '\0';
return result;
}
/* So, now let's reverse it so that we get "10" when we convert 10 */
STRCMP_EQUALS("10", itoa10(10, buffer));
char *itoa10(int value, char *buffer)
{
char *result = buffer;
do {
*buffer++ = '0' + value % 10;
value /= 10;
} while (value > 0);
*buffer = '\0';
return strrev(result);
}
/* We haven't dealt with negative numbers yet, so let's do it */
STRCMP_EQUALS("-1", itoa10(-1, buffer));
static int abs(int value)
{
return value < 0 ? -value : value;
}
char *itoa10(int value, char *buffer)
{
char *result = buffer;
int current = value;
do {
*buffer++ = '0' + abs(current % 10);
current /= 10;
} while (current != 0);
if (value < 0)
*buffer++ = '-';
*buffer = '\0';
return strrev(result);
}
/* That is one dense piece of code. What can we do to clean it up? */
/* We can extract a little chunk.. naming it int_to_revstring */
static int abs(int value)
{
return value < 0 ? -value : value;
}
static void int_to_revstring(int value, char *buffer)
{
int current = value;
do {
*buffer++ = '0' + abs(current % 10);
current /= 10;
} while (current != 0);
if (value < 0)
*buffer++ = '-';
*buffer = '\0';
}
char *itoa10(int value, char *buffer)
{
int_to_revstring(value, buffer);
return strrev(buffer);
}
/* But int_to_revstring is still a little dense. It would
be clearer if it only dealt with non-negatives */
/* When we separate the logic for negative numbers and non-negative numbers
we don't need abs any more, and the code reads well. */
static void nonneg_int_to_revstring(int value, char *buffer)
{
do {
*buffer++ = '0' + value % 10;
value /= 10;
} while (value > 0);
*buffer = '\0';
}
static void int_to_revstring(int value, char *buffer)
{
if (value >= 0)
nonneg_int_to_revstring(value, buffer);
else {
nonneg_int_to_revstring(-value, buffer);
strcat(buffer, "-");
}
}
char *itoa10(int value, char *buffer)
{
int_to_revstring(value, buffer);
return strrev(buffer);
}
/* This is pretty clear, but I'm not happy with it.
Yes, the functions are small, but 'reverse strings' are just
an alien concept. */
/* Rolling back to the denser code and dropping the magic number */
static int abs(int value)
{
return value < 0 ? -value : value;
}
char *itoa10(int value, char *buffer)
{
char *result = buffer;
int current = value;
const int radix = 10;
do {
*buffer++ = '0' + abs(current % radix);
current /= radix;
} while (current != 0);
if (value < 0)
*buffer++ = '-';
*buffer = '\0';
return strrev(result);
}
/* Isn't it interesting that this denser code contains the concept
of a reversed string representation of an int, but that concept
doesn't seem to sit well on its own?
What do you think? */
!commentForm
Hi Michael, it seems to me that there's a concept lurking here called "least significant digit" it is an important concept because your implementation immediately jumps to the use of the modulus operator to generate the digits in the result, which naturally gets them in "least significant" to "most significant" order. This is arguably "simplest", and is certainly most efficient for the computer. But it's easy (for me) to imagine a 5th grader who's mastering "powers of ten" working out the digits in the opposite (and unreversed) order. I also tend to look at the most significant digits first (on bank statements, in experimental data, etc :)
I suppose it is a matter of taste whether introducing a simple "explaining variable" helps to explain what's going on, or at least points the reader of the code to the right technical idea to understand ...something like
I really like this example because it reminds me of two things that are easy to forget:
1) Sometimes it is really hard to make the code express everything, and from my experience this can be especially true for mathematical algorithms. Just look at code for FFTs, for Gaussian elimination, for numerical solution of differential equations: there exists amazingly good code for carrying out these tasks, but their usability hinges crucially on the quality of documentation and background theory that comes with them.
2) I can't imagine any simple path for refactoring from a "most significant digit first" algorithm to this clean, efficient one. Programmers shouldn't forget the "Substitute Algorithm" refactoring!
''Les, I don't see a easy way of going there either. It's great to have the passing tests to help in the move though. MichaelFeathers''
I suppose it is a matter of taste whether introducing a simple "explaining variable" helps to explain what's going on, or at least points the reader of the code to the right technical idea to understand ...something like
char *itoa10(int value, char *buffer)
{
char *result = buffer;
int remainder = value;
int lst_sig_dig = abs(remainder % radix);
const int radix = 10;
do {
*buffer++ = lst_sig_dig + '0';
remainder /= radix;
lst_sig_dig = abs(remainder % radix);
} while (remainder != 0);
if (value < 0)
*buffer++ = '-';
*buffer = '\0';
return strrev(result);
}
I really like this example because it reminds me of two things that are easy to forget:
1) Sometimes it is really hard to make the code express everything, and from my experience this can be especially true for mathematical algorithms. Just look at code for FFTs, for Gaussian elimination, for numerical solution of differential equations: there exists amazingly good code for carrying out these tasks, but their usability hinges crucially on the quality of documentation and background theory that comes with them.
2) I can't imagine any simple path for refactoring from a "most significant digit first" algorithm to this clean, efficient one. Programmers shouldn't forget the "Substitute Algorithm" refactoring!
''Les, I don't see a easy way of going there either. It's great to have the passing tests to help in the move though. MichaelFeathers''
Oops, of course "lst_sig_dig" should be declared after "radix" in the snippet I provided, sigh.
This article is more than a tad obfuscated: You never actually explain what it is you mean by "concepts that don't like to be named;" yet you use the term twice. I'm left with the impression that you think that the notion of producing a reversed string is a sufficiently obtuse concept that it should not be dignified with a named symbol in the program.
However, I've since decided that the concept you didn't want to name is the fact that your 2nd to last program fails the test case for MIN_INT/INT_MIN. As it turns out, -INT_MIN == INT_MIN; so you'll need to convert nonneg_int_to_revstring() to accept unsigned int, or at least use an unsigned radix. Fortunately, your final version passes the test because it uses abs() around the signed modulo operator. ;-)
Seriously though: What do you really mean by "Concepts that don't like to be named?"
Yes, I was referring to fact that a reverse string is pretty obtuse, not the concept itself, but it seems very "low weight" to have functions that operate on it. Re the cases for INT_MIN, that's the way TDD is done. You don't get to the case for INT_MIN until you get to the case for INT_MIN. If, for instance, I was writing a Stack, I might go through a couple cases for pop() before ever getting to a case for 'pop on empty.' If you look at the intermediate implementations for pop() you'd go "oh wow it has a bug" but not really, it's just not done yet. It's the price you pay for doing things in small steps. The benefit you get is feedback on your partial implementations. -- Michael Feathers
However, I've since decided that the concept you didn't want to name is the fact that your 2nd to last program fails the test case for MIN_INT/INT_MIN. As it turns out, -INT_MIN == INT_MIN; so you'll need to convert nonneg_int_to_revstring() to accept unsigned int, or at least use an unsigned radix. Fortunately, your final version passes the test because it uses abs() around the signed modulo operator. ;-)
Seriously though: What do you really mean by "Concepts that don't like to be named?"
Yes, I was referring to fact that a reverse string is pretty obtuse, not the concept itself, but it seems very "low weight" to have functions that operate on it. Re the cases for INT_MIN, that's the way TDD is done. You don't get to the case for INT_MIN until you get to the case for INT_MIN. If, for instance, I was writing a Stack, I might go through a couple cases for pop() before ever getting to a case for 'pop on empty.' If you look at the intermediate implementations for pop() you'd go "oh wow it has a bug" but not really, it's just not done yet. It's the price you pay for doing things in small steps. The benefit you get is feedback on your partial implementations. -- Michael Feathers
http://www.opengroup.org/pubs/online/7908799/xsh/sscanf.html
http://www.cplusplus.com/ref/cstdio/sscanf.html
Looks like there is an okay way to convert strings to integers.
http://www.cplusplus.com/ref/cstdio/sscanf.html
Looks like there is an okay way to convert strings to integers.
I don't see a problem with reversing strings. I do that all the time, and I've found clever ways to do that in 1 liners, reversing in place.
The only thing that I dislike of your itoa implementation, is that the buffer must be big enough to hold the data. And the buffer must be passed as parameter, so how do I know if the buffer I'm passing is big enough? Will it core dump?
The caller has 3 options:
1. Call malloc before calling itoa, then free when done:
char * data = (char *) malloc( 10 + number );
char * result = itoa( number, data, 10 );
... use the result ...
free( data );
Notice I've removed the check of data == null after malloc for brevity.
2. Use an array and never care to return the memory because it is automatic.
char data[2048];
char * result = itoa( number, data, 10 );
... use the result ...
The problem with this is that if you call itoa several times, you need to make sure you are using differente data to hold the result. This makes the code incredibly hard to use and make you wish you worked in Java or Smalltalk.
3. Create an String class (in C++) which handles all that stuff automatically, calling itoa when apropiate and returning the memory as needed.
Unfortunately, a lot of this is just "life in C." There are some people who work in C environments and they, for some reason political or technical, can't use C++. For better or worse, in C you have to know your bounds. -- MichaelFeathers
The only thing that I dislike of your itoa implementation, is that the buffer must be big enough to hold the data. And the buffer must be passed as parameter, so how do I know if the buffer I'm passing is big enough? Will it core dump?
The caller has 3 options:
1. Call malloc before calling itoa, then free when done:
char * data = (char *) malloc( 10 + number );
char * result = itoa( number, data, 10 );
... use the result ...
free( data );
Notice I've removed the check of data == null after malloc for brevity.
2. Use an array and never care to return the memory because it is automatic.
char data[2048];
char * result = itoa( number, data, 10 );
... use the result ...
The problem with this is that if you call itoa several times, you need to make sure you are using differente data to hold the result. This makes the code incredibly hard to use and make you wish you worked in Java or Smalltalk.
3. Create an String class (in C++) which handles all that stuff automatically, calling itoa when apropiate and returning the memory as needed.
Unfortunately, a lot of this is just "life in C." There are some people who work in C environments and they, for some reason political or technical, can't use C++. For better or worse, in C you have to know your bounds. -- MichaelFeathers
Add Child Page to ConceptsThatDontLikeToBeNamed