Convex Hull Timing
In a recent post comparing the timing of C++, Java, and Ruby, one of the participants (xreborner) submitted the code for a convex hull algorithm. It's been a while since I've done any computational geometry, so I found myself intrigued.
The algorithm used by xreborner looks like a Graham Scan, which has an O(nLogn) performance. Indeed, the time used by this algorithm is dominated by a quicksort.
There is another algorithm known as a Jarvis March, otherwise known as the giftwrapping algorith. It has a complexity of O(kn) where k is the number of points in the resulting hull.
I got curious about which of these would really be faster. Clearly O(nLogn) is better than O(kn) only if logn < k. But there's another issue. The algorithm for the Jarvis March is much simpler than the Graham Scan. It seems to me that the the crossover point might be large enough to make the Jarvis March the better choice for a large number of cases. So I wrote the Jarvis March algorith and compared the speed to xreborners Graham Scan. The results, and my Jarvis March code are below.
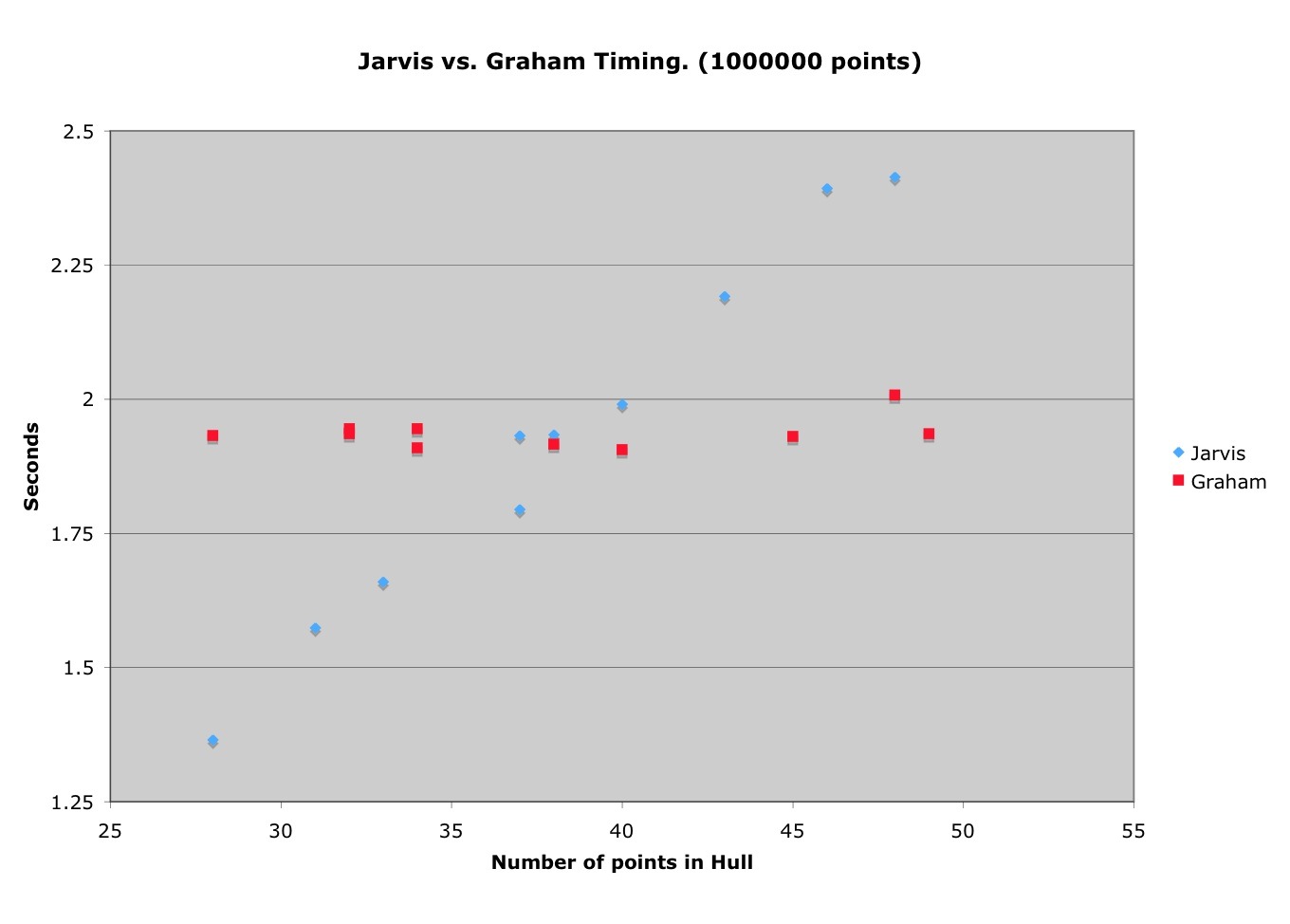
Isn't that interesting? I created a million random points and plotted the time vs. the number of vertices discovered. The crossover seems to be right at the midpoint of the random distribution of vertices! Right at 37ish points. I suppose this is a coincindence, but it's kind of spooky.
Oh, as an experiment, see if you can read the Jarvis March code and understand the algorithm. Then see if you can read the Graham Scan algorithm and understand it.
import java.util.*;
public class JarvisMarch {
Points pts;
private Points hullPoints = null;
private List<Double> hy;
private List<Double> hx;
private int startingPoint;
private double currentAngle;
private static final double MAX_ANGLE = 4;
public JarvisMarch(Points pts) {
this.pts = pts;
}
/**
* The Jarvis March, sometimes known as the Gift Wrap Algorithm.
* The next point is the point with the next largest angle.
* <p/>
* Imagine wrapping a string around a set of nails in a board. Tie the string to the leftmost nail
* and hold the string vertical. Now move the string clockwise until you hit the next, then the next, then
* the next. When the string is vertical again, you will have found the hull.
*/
public int calculateHull() {
initializeHull();
startingPoint = getStartingPoint();
currentAngle = 0;
addToHull(startingPoint);
for (int p = getNextPoint(startingPoint); p != startingPoint; p = getNextPoint(p))
addToHull(p);
buildHullPoints();
return hullPoints.x.length;
}
public int getStartingPoint() {
return pts.startingPoint();
}
private int getNextPoint(int p) {
double minAngle = MAX_ANGLE;
int minP = startingPoint;
for (int i = 0; i < pts.x.length; i++) {
if (i != p) {
double thisAngle = relativeAngle(i, p);
if (thisAngle >= currentAngle && thisAngle <= minAngle) {
minP = i;
minAngle = thisAngle;
}
}
}
currentAngle = minAngle;
return minP;
}
private double relativeAngle(int i, int p) {return pseudoAngle(pts.x[i] - pts.x[p], pts.y[i] - pts.y[p]);}
private void initializeHull() {
hx = new LinkedList<Double>();
hy = new LinkedList<Double>();
}
private void buildHullPoints() {
double[] ax = new double[hx.size()];
double[] ay = new double[hy.size()];
int n = 0;
for (Iterator<Double> ix = hx.iterator(); ix.hasNext();)
ax[n++] = ix.next();
n = 0;
for (Iterator<Double> iy = hy.iterator(); iy.hasNext();)
ay[n++] = iy.next();
hullPoints = new Points(ax, ay);
}
private void addToHull(int p) {
hx.add(pts.x[p]);
hy.add(pts.y[p]);
}
/**
* The PseudoAngle is a number that increases as the angle from vertical increases.
* The current implementation has the maximum pseudo angle < 4. The pseudo angle for each quadrant is 1.
* The algorithm is very simple. It just finds where the angle intesects a square and measures the
* perimeter of the square at that point. The math is in my Sept '06 notebook. UncleBob.
*/
public static double pseudoAngle(double dx, double dy) {
if (dx >= 0 && dy >= 0)
return quadrantOnePseudoAngle(dx, dy);
if (dx >= 0 && dy < 0)
return 1 + quadrantOnePseudoAngle(Math.abs(dy), dx);
if (dx < 0 && dy < 0)
return 2 + quadrantOnePseudoAngle(Math.abs(dx), Math.abs(dy));
if (dx < 0 && dy >= 0)
return 3 + quadrantOnePseudoAngle(dy, Math.abs(dx));
throw new Error("Impossible");
}
public static double quadrantOnePseudoAngle(double dx, double dy) {
return dx / (dy + dx);
}
public Points getHullPoints() {
return hullPoints;
}
public static class Points {
public double x[];
public double y[];
public Points(double[] x, double[] y) {
this.x = x;
this.y = y;
}
// The starting point is the point with the lowest X
// With ties going to the lowest Y. This guarantees
// that the next point over is clockwise.
int startingPoint() {
double minY = y[0];
double minX = x[0];
int iMin = 0;
for (int i = 1; i < x.length; i++) {
if (x[i] < minX) {
minX = x[i];
iMin = i;
} else if (minX == x[i] && y[i] < minY) {
minY = y[i];
iMin = i;
}
}
return iMin;
}
}
}
!commentForm -r
The previous timings were based upon a uniform random distribution of a million points, which tends to make hulls of 25-50 points. If, however, the points have a normal (Gaussian) distribution, then the hulls tend to have 13-18 verteces, which means that the Jarvis March is a much better algorithm for these distributions.
Sorry, I didn't descript my opinion very clearly. What I mean is that: Sure, The size of the hull for a uniform random distribution of points on a 2-D plane is averagely O(log n), which can be strictly proved. However, in practice, the distribution of data is unknown and sometimes abnormal, so there is a high probability that the size of the hull is much larger than O(log n). In such case, Graham Scan will be more stable and have a lower averagely time complexity on total.
For Jarvis March, although the algorithm looks simple and is easy to understand, however, its implementation is not so easy. You must compute and compare the angles, which may introduce some errors. You must deal with the case when two points have the same angle (where the distances has to be considered), and if the two angles are very close, you must determine whether they are really different or it is caused just by the computation error.
For Jarvis March, although the algorithm looks simple and is easy to understand, however, its implementation is not so easy. You must compute and compare the angles, which may introduce some errors. You must deal with the case when two points have the same angle (where the distances has to be considered), and if the two angles are very close, you must determine whether they are really different or it is caused just by the computation error.
Yes, it's true that the size of the hull for a random distribution of points is on the order of 25-50, whereas the ln of 1000000 is on the order of 14. Since it's true that the crossover for these two instances of the algorithm seems to be at 38, it is reasonable to suggest that the inner loop of the jarvis march is 2-3 times faster than the inner loop of the Graham Scan (i.e. the sort followed by the scan itself).
The point is that the O() number is a coefficient, not an absolute. The timing for the Graham Scan is O(N ln N)Kg. The timing for the Jarvis March O(NH)Kj. In this case Kj < 2Kg. So for H smaller than about 38, the Jarvis March is a better algorithm. Indeed, since the average number of hull point is also 38 (a very interesting coincidence) the statistical average performance of the Jarvis march is roughly the same as the graham scan.
So, if the input points are randomly distributed, and you are interested more in statistical performance rather than absolute time limits, there's no overwhelming reason to choose one program over the other. On the other hand if you want very consistent results then the Graham Scan is better. If you know the number of hull points will usually be less than the average then the Jarvis March is the better choice. If you know that the input points are currently close to the hull then the Graham scan is much better.
The point is that the O() number is a coefficient, not an absolute. The timing for the Graham Scan is O(N ln N)Kg. The timing for the Jarvis March O(NH)Kj. In this case Kj < 2Kg. So for H smaller than about 38, the Jarvis March is a better algorithm. Indeed, since the average number of hull point is also 38 (a very interesting coincidence) the statistical average performance of the Jarvis march is roughly the same as the graham scan.
So, if the input points are randomly distributed, and you are interested more in statistical performance rather than absolute time limits, there's no overwhelming reason to choose one program over the other. On the other hand if you want very consistent results then the Graham Scan is better. If you know the number of hull points will usually be less than the average then the Jarvis March is the better choice. If you know that the input points are currently close to the hull then the Graham scan is much better.
the size of the hull is much larger than the number of points
should be
the size of the hull is much larger than the logarithm of the number of points
should be
the size of the hull is much larger than the logarithm of the number of points
Graham Scan and Jarvis March should be used in different situation. In some cases of practice, the size of the hull is much larger than the number of points, hence the speed of Graham Scan is more stable. Moreover, a test between different languages' implementations on diffetent algorithms seems nonsense.
Add Child Page to ConvexHullTiming