The Speed of Java, C++, and Ruby
You might find the following chart interesting. It shows the same "Sieve of Eratoshthenes" algorithm in Ruby, Java, and C++. I've posted the code at the end of this article.
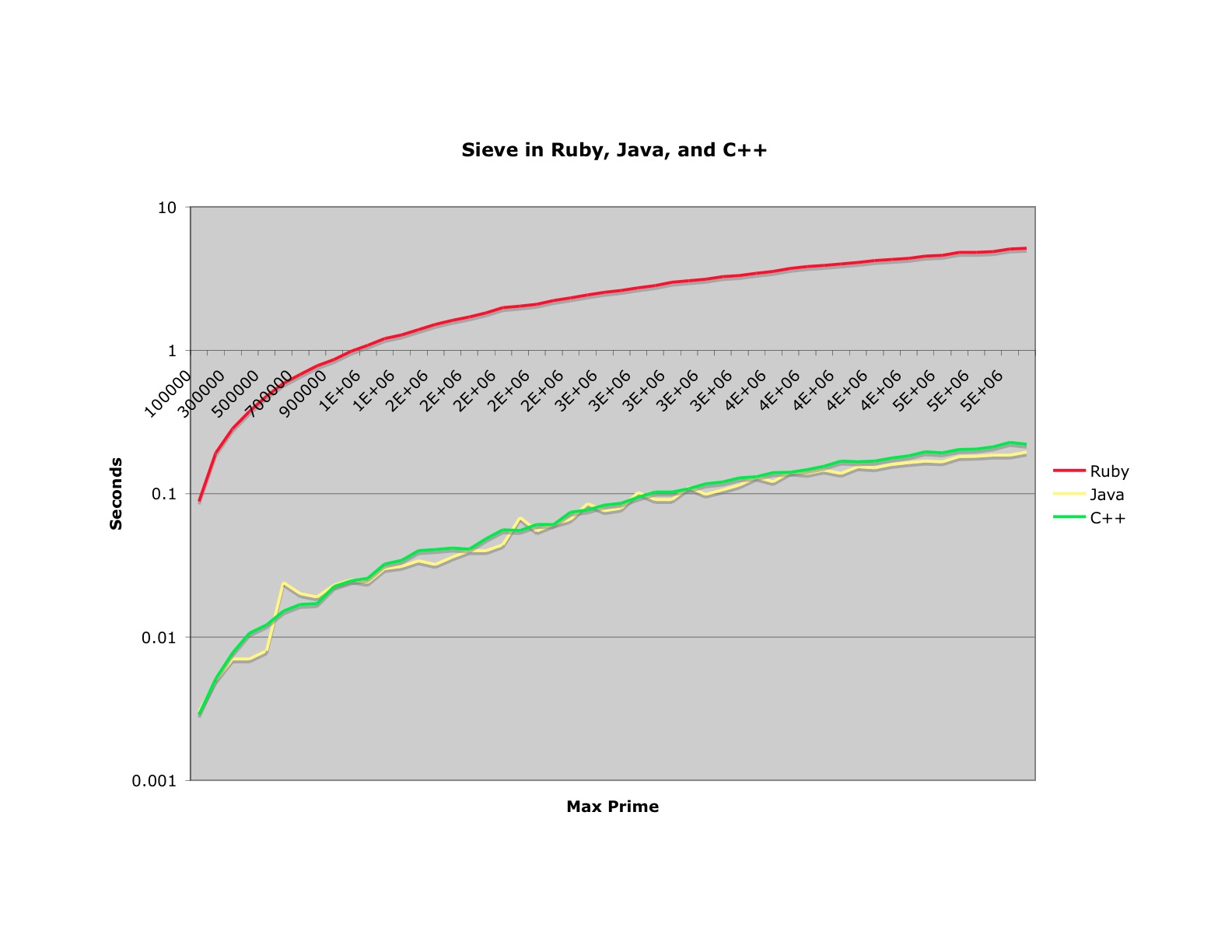
OK, clearly Ruby is slow, by about 1.5 orders of magnitude. That's not great news for the Ruby crowd. On the other hand, Oh boo hoo! Ruby is as fast as a top-flight machine 5 or 6 years ago. My heart bleeds. When I remember the miracles we were able to perform on machines with a cycle time of less than a megahertz...and we walked uphill both ways!
Notice that all three curves are the same shape. And as we learned in my previous blog that shape is perversely linear. Finally notice that the Java curve is just a wee bit faster than the C++ curve. You can blame this on the non-optimized gcc compiler I was using (cygwin) but again: Oh boo hoo!. If there are any C++ programmers out there who smirk at the supposed slowness of Java, I think you'd better reconsider.
And for you Java programmers who are smirking because your environment is 30X faster than Ruby, I'm sure a ruby jitter is going to show up. And anyway, I'd rather have simple, clean, maintainable code over even 1.5 orders of magnitude in many cases.
Ruby
require 'benchmark'
def sievePerformance(n)
r = Benchmark.realtime() do
sieve = Array.new(n,true)
sieve[0..1] = [false,false]
2.upto(Integer(Math.sqrt(n)) do |i|
if sieve[i]
(2*i).step(n,i) do |j|
sieve[j] = false
end
end
end
end
r
end
Java
public class GeneratePrimes {
public static double generate(int max) {
long start = System.currentTimeMillis();
boolean sieve[] = new boolean[max];
Arrays.fill(sieve, true);
sieve[0] = false;
sieve[1] = false;
for (int i = 2; i < Math.sqrt(max); i++) {
if (sieve[i]) {
for (int j = 2*i; j < sieve.length; j+=i) {
sieve[j]= false;
}
}
}
return (System.currentTimeMillis() - start)/1000.0;
} C++
#include <iostream>>
#include <math.h>
#include <sys/time.h>
using namespace std;
double generate(int max) {
struct timeval start;
struct timezone tz;
gettimeofday(&start, &tz);
bool *sieve = new bool[max];
for (int i=0; i<max; i++) sieve[i] = true;
sieve[0] = false;
sieve[1] = false;
for (int n=2; n<sqrt(max); n++) {
if (sieve[n]) {
for (int j=2*n; j<max; j+=n)
sieve[j] = false;
}
}
struct timeval end;
gettimeofday(&end, &tz);
double startSecond = start.tv_usec/1000000.0;
double endSecond = (end.tv_sec - start.tv_sec) + end.tv_usec/1000000.0;
return endSecond - startSecond;
}
int main(int ac, char** av) {
for (int i=100000; i<=5000000; i+=100000) {
double time = generate(i);
cout << time << endl;
}
}
!commentForm -r
[ Once again, with formatting. ]
This Common Lisp function, compiled with SBCL, is more than twice as fast as Java on my laptop (Java takes 6.831 seconds to compute the primes up to 10 million, Lisp takes 2.825):
Not only is it faster, it is shorter than the other implementations.
Regards,
Patrick
This Common Lisp function, compiled with SBCL, is more than twice as fast as Java on my laptop (Java takes 6.831 seconds to compute the primes up to 10 million, Lisp takes 2.825):
(defun sieve (max)
"Compute primes up to MAX using the Sieve of Erastothenes."
(declare (type fixnum max))
(let ((results (make-array max :element-type 'bit :initial-element 1))
(sqrt-max (isqrt max)))
(declare (type fixnum sqrt-max))
(setf (aref results 0) 0)
(setf (aref results 1) 0)
(dotimes (i sqrt-max)
(when (= (aref results i) 1)
(do ((j (* 2 i) (+ j i)))
((> j (- max i)))
(setf (aref results j) 0))))))
Not only is it faster, it is shorter than the other implementations.
Regards,
Patrick
This Common Lisp function, compiled with SBCL, is more than twice as fast as Java on my laptop (Java takes 6.831 seconds to compute the primes up to 10 million, Lisp takes 2.825):
(defun sieve (max)
"Compute primes up to MAX using the Sieve of Erastothenes."
(declare (type fixnum max))
(let ((results (make-array max :element-type 'bit :initial-element 1))
(sqrt-max (isqrt max)))
(declare (type fixnum sqrt-max))
(setf (aref results 0) 0)
(setf (aref results 1) 0)
(dotimes (i sqrt-max)
(when (= (aref results i) 1)
(do ((j (* 2 i) (+ j i)))
((> j (- max i)))
(setf (aref results j) 0))))))
Not only is it faster, it is shorter than the other implementations.
Regards,
Patrick
(defun sieve (max)
"Compute primes up to MAX using the Sieve of Erastothenes."
(declare (type fixnum max))
(let ((results (make-array max :element-type 'bit :initial-element 1))
(sqrt-max (isqrt max)))
(declare (type fixnum sqrt-max))
(setf (aref results 0) 0)
(setf (aref results 1) 0)
(dotimes (i sqrt-max)
(when (= (aref results i) 1)
(do ((j (* 2 i) (+ j i)))
((> j (- max i)))
(setf (aref results j) 0))))))
Not only is it faster, it is shorter than the other implementations.
Regards,
Patrick
In situations where Java ***GUI*** code and C++ GUI code are compared, the differences in speed are very obvious. Of course, there is (obviously) no "standard" for C++ GUI code (unless you count the pseudo-emerging Qt-standard) so this only applies to native API impls, which is, literally, comparing Apples to Weenies.
In 1997, I was at American Express *promoting* their use of Java for their needs and coming up against the "speed" issue. I demonstrated "speed" by writing a very simple app that grabbed the contents of a remote web site in 7 lines of "real code" (not counting import statements). It executed almost instantaneously on a P5-133MHz machine. I even showed comparisons of speed in a number of different non-GUI algorithms, including Towers of Hanoi. Performance was, at worst, within a few percentage points of "native" C++ code. I felt that the demonstrated "I wrote this code in about 2 minutes" speed was more readily important (to a company spending millions upon millions in developer resources) than the few added microseconds of latency spent processing Java bytecodes compared to C++ executables. Of course, that is when I stepped on the unspoken "third rail" of development, which is basically anytime you bring into question the value of having a staff of 160+ people to do the work of 3 or 4 "core" developers. Some topics are just not very politically correct in the real world! :D
Take Care.
Rob!
In 1997, I was at American Express *promoting* their use of Java for their needs and coming up against the "speed" issue. I demonstrated "speed" by writing a very simple app that grabbed the contents of a remote web site in 7 lines of "real code" (not counting import statements). It executed almost instantaneously on a P5-133MHz machine. I even showed comparisons of speed in a number of different non-GUI algorithms, including Towers of Hanoi. Performance was, at worst, within a few percentage points of "native" C++ code. I felt that the demonstrated "I wrote this code in about 2 minutes" speed was more readily important (to a company spending millions upon millions in developer resources) than the few added microseconds of latency spent processing Java bytecodes compared to C++ executables. Of course, that is when I stepped on the unspoken "third rail" of development, which is basically anytime you bring into question the value of having a staff of 160+ people to do the work of 3 or 4 "core" developers. Some topics are just not very politically correct in the real world! :D
Take Care.
Rob!
I'v tried the bench with YARV (http://www.atdot.net/yarv/) - this gave on average 3x-4x speed increase over the default ruby interpreter. It's still far cry from compiled languages (10x-15x slower than the C++ code) but i'd say its not _that_ bad for scripted language. It's getting very close to Squeak smalltalk. Of course this is just one math bench, id like to see how it compares when it comes to production code with lots of overhead in the form of complex class hierarchies and string processing. The future of ruby will definitely depend on how ruby2.0/rite will turn out in the terms of speed.
Hi Folks,
I collected a bunch of data on Smalltalk vs. Java and Ruby (I'm not really interested in C performance).
The algorithms I used are without sqrt, they are clearer aren't they?
** Java **
** Ruby **
**Smalltalk**
Java is the winner, for 2100000 it spends 250 msec on average. Ruby 6500 msec on average. Squeak Smalltalk 2269 msec, VisualWorks[?] Smalltalk 460 msec.
I think the syntax of Smalltalk is really clear, the clearest in my opinion. It's a bit unusual especially if you come from a classic programming language, but shortly it becomes handy.
Tools: Win xp on a 3ghz intel, JDK 1.4.2_07, Ruby 1.8.1, VisualWorks[?]
I collected a bunch of data on Smalltalk vs. Java and Ruby (I'm not really interested in C performance).
The algorithms I used are without sqrt, they are clearer aren't they?
** Java **
public class GeneratePrimes {
public static double generate(int n) {
long start = System.currentTimeMillis();
boolean sieve[] = new boolean[n];
Arrays.fill(sieve, true);
sieve[0] = false;
sieve[1] = false;
for (int i = 2; i < n; i++) {
if (sieve[i]) {
for (int j = 2 * i; j < n; j += i) {
sieve[j] = false;
}
}
}
return (System.currentTimeMillis() - start);
}
}
** Ruby **
require 'benchmark'
def sievePerformance(n)
r = Benchmark.realtime() do
sieve = Array.new(n,true)
sieve[0..1] = [false,false]
2.upto(n) do |i|
if sieve[i]
(2*i).step(n,i) do |j|
sieve[j] = false
end
end
end
end
puts r
end
**Smalltalk**
runOn: aNumber
| sieve |
sieve := Array new: aNumber withAll: true.
sieve at: 1 put: false.
2 to: aNumber do: [:i | (sieve at: i) ifTrue: [2 * i to: aNumber by: i do: [:k | sieve at: k put: false]]].
^sieve
Java is the winner, for 2100000 it spends 250 msec on average. Ruby 6500 msec on average. Squeak Smalltalk 2269 msec, VisualWorks[?] Smalltalk 460 msec.
I think the syntax of Smalltalk is really clear, the clearest in my opinion. It's a bit unusual especially if you come from a classic programming language, but shortly it becomes handy.
Tools: Win xp on a 3ghz intel, JDK 1.4.2_07, Ruby 1.8.1, VisualWorks[?]
- .3, Squeak 3.8-6665
Please omit my previously comment.
that's wrong.
I test the program use calloc. it is much faster.
And I also ask a Javaer, he tell me Arrays.fill seems the same with "for (int i=0; i<max; i++) sieve[i] = true;"
So it seems allocation take 99% of time, this compare shows us nothing.
that's wrong.
I test the program use calloc. it is much faster.
And I also ask a Javaer, he tell me Arrays.fill seems the same with "for (int i=0; i<max; i++) sieve[i] = true;"
So it seems allocation take 99% of time, this compare shows us nothing.
// for (int i=0; i<max; i++) sieve[i] = true;
memset(sieve, sizeof(bool) * max, true);
Please retest!
memset(sieve, sizeof(bool) * max, true);
Please retest!
Perl
#!/usr/bin/perl -w}
use Math::Prime::XS qw(sieve_primes);
sub generate {
return sieve_primes($_[1]);
Thanks, UB, for your time on clarifying this language problem. I think I can go ahead to take the "Possibly" in that comment as a polite way of saying "Unlikely".
I am not a native English speaker. I learned that "possibly" means minimal (almost zero) probability. Is that not so?
- No, it means "it is possible". It can be inflected (usually by rolling your eyes or overstressing the first sylable) to mean "unlikely", but by itself means that the probabilty is less than 1. -UB
- I agree. Iostream has nothing to do with this. That was my point all along. -UB.
to phoenixsh:
Actually, when n is small, C++ program is even 10x times faster than Java program in my machine. Okay, as what you said, n is usually small in practice, so C++ is usually much faster than Java in practice.
Actually, when n is small, C++ program is even 10x times faster than Java program in my machine. Okay, as what you said, n is usually small in practice, so C++ is usually much faster than Java in practice.
I didn't take account of the time of creating and initializing input data into the final measured time.
Yes, if the point is 2-dimensional and the coordinates are integers, you can use integers instead of points (you mean use a long instead of a class of two ints, right?). However, what can you do if the point is higher dinemsional or the coordinates are reals? And even if you can use integers instead of points, how ugly and complicated the program would be? The C++ program would be more beautiful, simple and easier-maintenance, and is still faster.
When I ran the Java program, I had increased the max heap size to 400m with the -Xmx400m. If your machine has a memory of 1000m, you can try to run the programs with a larger n, and you will still find that Java program uses much more memory.
At least at the present time, for nearly nothing, Java is faster than C++.
Java is a good language for, and only for OO programming. However, is OOP the panacea?
At least, I can use a complex or a big integer as like as an int in C++.
Yes, if the point is 2-dimensional and the coordinates are integers, you can use integers instead of points (you mean use a long instead of a class of two ints, right?). However, what can you do if the point is higher dinemsional or the coordinates are reals? And even if you can use integers instead of points, how ugly and complicated the program would be? The C++ program would be more beautiful, simple and easier-maintenance, and is still faster.
When I ran the Java program, I had increased the max heap size to 400m with the -Xmx400m. If your machine has a memory of 1000m, you can try to run the programs with a larger n, and you will still find that Java program uses much more memory.
At least at the present time, for nearly nothing, Java is faster than C++.
Java is a good language for, and only for OO programming. However, is OOP the panacea?
At least, I can use a complex or a big integer as like as an int in C++.
It might be less relevant here. But if you really need to compute convext hull for millions of points you could use probability techniques to exclude most points from actual computation. |x - a| + |y - b| > THRESHOLD would be a good filter here. Then you could sample one thousand (or one thousandth of total points if you like) points to determine (a, b) and THRESHOLD. If |x - a| >= |y - b|, then |x - a| + |y - b|>>2 is a better filter. (It's very good estimation to the distance between (x, y) and (a, b), see http://blog.csdn.net/phoenixsh/archive/2006/07/31/1005157.aspx for details (Chinese))
xreborner wrote the code below for the convex hull algorithm. He found that Java was 4X as long as C++. I compiled and ran these programs and found the same result. Then I profiled the Java version and found the following:
What this says is that almost half the time is spent in the compare function of the sort, and another large bulk in the sort code itself. Still another large bulk of time goes into creating and initializing the input data. Only 13% of the time went into the actual convex hull algorithm.
Now it seems to me that there are ways to speed up the comparison and the initialization. Specifically we could use arrays of integers instead of arrays of points. On the other hand that's not really the point. It would be absurd for me to claim that Java is always faster than C++. Clearly there are things that C++ can do better than Java. However, the difference is not that profound and, in fact, for some things Java is faster than C++. Morevoer Java is a much easier language to work in, and has much better tool support. Therefore it seems to me that unless you are working with extremely tight realtime constraints there is no compelling reason to use C++.
By the way, the memory problems that xreborner found are a result of the fact that the default JVM limits the maximum heap space to 16 meg. If you increase the max heap size to 1000m with the -Xmx1000m command line switch, the algorithm runs without exception.
Compiled + native Method
43.4% 89 + 0 Temp$PointComp.compare
19.5% 40 + 0 java.util.Arrays.mergeSort
17.6% 36 + 0 Temp.test
13.2% 27 + 0 Temp.compute_convex
93.7% 192 + 0 Total compiled
What this says is that almost half the time is spent in the compare function of the sort, and another large bulk in the sort code itself. Still another large bulk of time goes into creating and initializing the input data. Only 13% of the time went into the actual convex hull algorithm.
Now it seems to me that there are ways to speed up the comparison and the initialization. Specifically we could use arrays of integers instead of arrays of points. On the other hand that's not really the point. It would be absurd for me to claim that Java is always faster than C++. Clearly there are things that C++ can do better than Java. However, the difference is not that profound and, in fact, for some things Java is faster than C++. Morevoer Java is a much easier language to work in, and has much better tool support. Therefore it seems to me that unless you are working with extremely tight realtime constraints there is no compelling reason to use C++.
By the way, the memory problems that xreborner found are a result of the fact that the default JVM limits the maximum heap space to 16 meg. If you increase the max heap size to 1000m with the -Xmx1000m command line switch, the algorithm runs without exception.
The two statements seem synonymous to me.
I came across your Chinese blog (really yours?), where I found your words "Possibly, although iostream had very little to do with this algorithm." was translated to something like "Very likely, although this algorithm doesn't involve too much iostream". That isn't what you meant, is it?
I have made some mistake in the codes. "(long long)Seed * 103 & 65535" in random_short function should be changed to "(long long)Seed * 103 % Prime & 65535".
I have written a convex polygon computing algorithm, which computes the smallest convex polygon containg a given set of n points on the plane in O(n*log(n)) time. I implemented and tested it in C++ and Java. The result shows that Java is at least 5 times slower than C++, and is sometimes 10 times slower. Moreover, Java used much more memory than C++. In my 512MB RAM machine, the c++ program runs normally when n is larger than 20,000,000, while the Java program throws OutOfMemoryError[?] exception when n=12,000,000.
The codes are here:
C++ ( compiled in GCC with option -O3 ):
Java:
The codes are here:
C++ ( compiled in GCC with option -O3 ):
include <iostream>
include <cstdio>
include <algorithm>
include <ctime>
using namespace std;
struct point
{
int X, Y;
};
struct point_less
{
bool operator()(const point& A, const point& B) const
{
return A.X < B.X || A.X == B.X && A.Y < B.Y;
}
};
long long cross_mul(const point& O, const point& A, const point& B)
{
return (long long)(A.X - O.X) * (B.Y - O.Y) - (long long)(B.X - O.X) * (A.Y - O.Y);
}
int compute_convex(int N, point Points[])
{
sort(Points, Points + N, point_less());
if (N <= 1) return N;
int UN, LN;
point* Ups = new point[N];
point* Lows = new point[N];
UN = 1;
Ups[0] = Points[0];
for (int I = 1; I < N - 1; I++)
if (cross_mul(Ups[UN - 1], Points[I], Points[N - 1]) < 0)
{
while (UN >= 2 && cross_mul(Ups[UN - 2], Ups[UN - 1], Points[I]) >= 0) UN--;
Ups[UN++] = Points[I];
}
LN = 1;
Lows[0] = Points[N - 1];
for (int I = N - 2; I > 0; I--)
if (cross_mul(Lows[LN - 1], Points[I], Points[0]) < 0)
{
while (LN >= 2 && cross_mul(Lows[LN - 2], Lows[LN - 1], Points[I]) >= 0) LN--;
Lows[LN++] = Points[I];
}
int Result = UN + LN;
delete[] Ups;
delete[] Lows;
return Result;
}
short random_short(int& Seed)
{
static const int Prime = 2100000011;
if (Seed <= 0) Seed = 1;
Seed = int((long long)Seed * 101 % Prime);
return short((long long)Seed * 103 & 65535);
}
int random_int(int &Seed)
{
short A = random_short(Seed);
short B = random_short(Seed);
return (A << 16) | (B & 65535);
}
void test(int N)
{
int Seed = 0;
point* Points = new point[N];
for (int I = 0; I < N; I++)
{
Points[I].X = (random_int(Seed) & 0x7fffffff) % 100000000;
Points[I].Y = (random_int(Seed) & 0x7fffffff) % 100000000;
}
double Time = clock();
int Result = compute_convex(N, Points);
Time = (clock() - Time) / CLOCKS_PER_SEC;
delete[] Points;
cout << N << " " << Time << " " << Result << endl;
}
int main()
{
for (int I = 1; I <= 20; I++) test(1000000 * I);
printf("...");
scanf("%*s");
}
Java:
import java.util.*;
public class Temp {
public static class Point {
int x, y;
}
public static class PointComp implements Comparator {
public int compare(Object aObj, Object bObj) {
Point a = (Point)aObj;
Point b = (Point)bObj;
if (a.x < b.x) return -1;
if (a.x > b.x) return 1;
if (a.y < b.y) return -1;
if (a.y > b.y) return 1;
return 0;
}
}
public static long cross_mul(Point o, Point a, Point b) {
return (long)(a.x - o.x) * (b.y - o.y) - (long)(b.x - o.x) * (a.y - o.y);
}
public static int compute_convex(Point[] points) {
Arrays.sort(points, new PointComp());
int n = points.length;
if (n <= 1) return n;
int un, ln;
Point[] ups = new Point[n];
Point[] lows = new Point[n];
un = 1;
ups[0] = points[0];
for (int i = 1; i < n - 1; i++)
if (cross_mul(ups[un - 1], points[i], points[n - 1]) < 0)
{
while (un >= 2 && cross_mul(ups[un - 2], ups[un - 1], points[i]) >= 0) un--;
ups[un++] = points[i];
}
ln = 1;
lows[0] = points[n - 1];
for (int i = n - 2; i > 0; i--)
if (cross_mul(lows[ln - 1], points[i], points[0]) < 0)
{
while (ln >= 2 && cross_mul(lows[ln - 2], lows[ln - 1], points[i]) >= 0) ln--;
lows[ln++] = points[i];
}
return un + ln;
}
static int seed;
public static short random_short() {
final int prime = 2100000011;
if (seed <= 0) seed = 1;
seed = (int)((long)seed * 101 % prime);
return (short)((long)seed * 103 & 65535);
}
public static int random_int() {
short a = random_short();
short b = random_short();
return (a << 16) | (b & 65535);
}
public static void test(int n) {
seed = 0;
Point[] points = new Point[n];
for (int i = 0; i < n; i++) {
points[i] = new Point();
points[i].x = (random_int() & 0x7fffffff) % 100000000;
points[i].y = (random_int() & 0x7fffffff) % 100000000;
}
double time = System.currentTimeMillis();
int result = compute_convex(points);
time = (System.currentTimeMillis() - time) / 1000.0;
System.out.println(n + " " + time + " " + result);
}
public static void main(String[] args) {
for (int i = 1; i <= 20; i++) test(1000000 * i);
}
}
The simple test just proves that for some kind of very simple program Java can be as fast as C++. However, usually C++ would not be slower than Java. My first post is just to defend this.
I have tested Java and C++ on a more complicated algorithm, which shows that Java is much slower and space wasteful. In practice you can also see that CBuilder X is much slower than CBuilder 6.
I have tested Java and C++ on a more complicated algorithm, which shows that Java is much slower and space wasteful. In practice you can also see that CBuilder X is much slower than CBuilder 6.
| xreborner said: Mmm... I think the tested program is too simple. |
Mmm... I think the tested program is too simple. The slowness of Java is related with its inability to define simple structure (such as complex), lack of pointers, the absence of true templates, and of course the gc. Your simple program has nothing to do with these issues.
If you compare C++'s vector<int> with Java's ArrayList[?], C++'s map<int, complex<double> > with Java's Map, C++'s sort with Java's, and compare on some more complicated algorithm, I beleave that C++ will be much faster than Java.
If you compare C++'s vector<int> with Java's ArrayList[?], C++'s map<int, complex<double> > with Java's Map, C++'s sort with Java's, and compare on some more complicated algorithm, I beleave that C++ will be much faster than Java.
How do you quote in this blog?
You should be ashamed of your naked deletes! I would recommend vector<bool>, but it probably runs slower because it puts 8 bits per byte. My second option would be vector<char>.
You can surely make invent Boolean for C++. shared_ptr<bool const> is close, I think. My point is that you can't invent std::complez for Java, because the set of non reference objects is closed. Calculating something fast with complex numbers in java would require parallel arrays of floats to keep up with C++, losing OOness.
- I've been using tables: At the very beginning of a line put: |''put your quote here''| and make sure the character following the last vertical stroke is a return.
You should be ashamed of your naked deletes! I would recommend vector<bool>, but it probably runs slower because it puts 8 bits per byte. My second option would be vector<char>.
You can surely make invent Boolean for C++. shared_ptr<bool const> is close, I think. My point is that you can't invent std::complez for Java, because the set of non reference objects is closed. Calculating something fast with complex numbers in java would require parallel arrays of floats to keep up with C++, losing OOness.
Both the algorithm and the implementation is bad.
You should test the c++ performance using my code:
You should test the c++ performance using my code:
#include <cmath>
#include <ctime>
#include <iostream>
#include <algorithm>
#include <vector>
using namespace std;
void compute_primes(int Bound) // written by xreborner
{
bool* Marks = new bool[Bound];
fill(Marks, Marks + Bound, true);
int Sqrt = (int)sqrt(Bound - 1.0);
for (int I = 2; I <= Sqrt; I++)
if (Marks[I])
for (int J = I * I; J < Bound; J += I)
Marks[J] = false;
delete[] Marks;
}
int main()
{
vector<double> Times;
Times.reserve(50);
double Time = clock();
for (int I = 100000; I <= 5000000; I += 100000)
{
compute_primes(I);
double Temp = clock();
Times.push_back(Temp - Time);
Time = Temp;
}
for (int I = 0; I < (int)Times.size(); I++)
cout << Times[I] / CLOCKS_PER_SEC << endl;
}
| Thanks for the code. I see you've possibly corrected some off-by-one errors. Otherwise the algorithm seems identical. I ran your version and got results that were indistinguishable from mine. -UB |
[commentary]
myan is one of the most important translators of your book "Agile software programming, priciples..."
[original text]
Hi Uncle Bob, I'm not defending C++ but I truely believe that its inferior proformance is due to cygwin's bad implementation of iostream library.
Sure, Java is almost as fast as C and C++ now regarding to its execution speed. But its memory consumption is far larger not only than C and C++, but sometimes Python and Ruby. A realistic big Java application can easily eat up your gigabytes of memeory, which leads to frequent memeory-disk swap, and results in very bad overall performance. So I think the popular performance comparison with mathematical algorithms is not very convincing. That's my cent of point.
BTW, I fully appreciate your opinion and enthusiasm about Ruby, I hope and believe the future of programming belongs to freedom languages like Ruby and Python.
myan is one of the most important translators of your book "Agile software programming, priciples..."
[original text]
Hi Uncle Bob, I'm not defending C++ but I truely believe that its inferior proformance is due to cygwin's bad implementation of iostream library.
- Possibly, although iostream had very little to do with this algorithm. -UB
Sure, Java is almost as fast as C and C++ now regarding to its execution speed. But its memory consumption is far larger not only than C and C++, but sometimes Python and Ruby. A realistic big Java application can easily eat up your gigabytes of memeory, which leads to frequent memeory-disk swap, and results in very bad overall performance. So I think the popular performance comparison with mathematical algorithms is not very convincing. That's my cent of point.
- I'll grant you that the JVM can be large. However, if you assume it's already there, then the size of the bytecodes for the application itself need not be very large at all. And the heap can be constrained to a relatively small size to prevent virtual memory thrashing. So, if _engineered_ a java app should give a C++ app a run for it's money in most cases. -UB
BTW, I fully appreciate your opinion and enthusiasm about Ruby, I hope and believe the future of programming belongs to freedom languages like Ruby and Python.
Dear Uncle Bob,
As the chinese version of this blog was published in China, we got over dozens of feedback not even within a night. (Well, that's much more than your original post, now you can see the enthusiasm of Chinese people :-) )
Some of the comments agree with you, and sure there are always some quite the opposite. But I think the best part is that some professional engineers gave really thoughtful comments and also questions, and I will list some of the typical ones here, hope you can give them some precious comments...
As the chinese version of this blog was published in China, we got over dozens of feedback not even within a night. (Well, that's much more than your original post, now you can see the enthusiasm of Chinese people :-) )
Some of the comments agree with you, and sure there are always some quite the opposite. But I think the best part is that some professional engineers gave really thoughtful comments and also questions, and I will list some of the typical ones here, hope you can give them some precious comments...
| I believe the speed of Java would be worst if you used Boolean instead of boolean. That's the edge of C++. |
| You're leaking the bool array. |
- Sigh. That's the edge of Java.
You're leaking the bool array.
I believe the speed of Java would be worst if you used Boolean instead of boolean. That's the edge of C++.
I believe the speed of Java would be worst if you used Boolean instead of boolean. That's the edge of C++.
The question becomes how fast do you need it to be?
Andrew,
Certainly you are correct. The fact that a loop in Java executes at the same speed as a loop in C does not mean that the Java environment is faster than the C environment. However, that goes more towards the design of the environment than the language itself. You also make a good point that the jitter will have it's own performance idiosyncracies and that load time is an issue. However, IMHO these are secondary and tertiary effects. The primary effect is that applications can be made to execute very very fast, and that the speed advantage of C/C++ has been marginalized by the ease of java development. The tools in the java space far exceed the tools in the C/C++ space, to the extent that develoment in Java is Nx faster than C/C++ where N approaches 3.
Certainly you are correct. The fact that a loop in Java executes at the same speed as a loop in C does not mean that the Java environment is faster than the C environment. However, that goes more towards the design of the environment than the language itself. You also make a good point that the jitter will have it's own performance idiosyncracies and that load time is an issue. However, IMHO these are secondary and tertiary effects. The primary effect is that applications can be made to execute very very fast, and that the speed advantage of C/C++ has been marginalized by the ease of java development. The tools in the java space far exceed the tools in the C/C++ space, to the extent that develoment in Java is Nx faster than C/C++ where N approaches 3.
Timed line for line like this, Java should be able to come out in front.
In fact, with a good optimising JustInTime[?] compiler that analyses run-time behaviour to optimise the machine code it generates for execution, it has quite an advantage. Though some C compilers come with utilities to allow this to be done also, but as a manual optimisation stage (compile, run with profile, re-compile based on profile).
However, the reality for me has always been that Java just seems to be slower in practise, and many other people have related the same experience to me. I think it has more to do with the behaviours of more typical non-compute bound programs.
It may be the fact that there's s JVM involved, so there's massively more memory utilised.
It may be the startup time, JIT processing etc.
It may be the libraries (Java application displays seem to update more clunkily that C/C++).
In summary, I don't think that compute-bound comparisons address the real issues.
...AndrewD[?]...
In fact, with a good optimising JustInTime[?] compiler that analyses run-time behaviour to optimise the machine code it generates for execution, it has quite an advantage. Though some C compilers come with utilities to allow this to be done also, but as a manual optimisation stage (compile, run with profile, re-compile based on profile).
However, the reality for me has always been that Java just seems to be slower in practise, and many other people have related the same experience to me. I think it has more to do with the behaviours of more typical non-compute bound programs.
It may be the fact that there's s JVM involved, so there's massively more memory utilised.
It may be the startup time, JIT processing etc.
It may be the libraries (Java application displays seem to update more clunkily that C/C++).
In summary, I don't think that compute-bound comparisons address the real issues.
...AndrewD[?]...
In python, the profilers and debuggers grab an interpreter hook and that slows things down a bit. Does the benchmark package do more than just acquire the time, as is done in the other code samples? If so, I would very much like to see this re-run without 'benchmark', getting time by some other means. Mind you, python is slower than C++ and Ruby also, but if it is grabbing an interpreter hook it is also slower than normal python.
Can you give us on what kind of hardware this bench was performed please ?
Add Child Page to SpeedOfJavaCppRuby